Московский экономический журнал 5/2017
УДК 339.13

Плотников Андрей Викторович,
кандидат экономических наук
доцент кафедры менеджмента
ФГБОУ ВО «Пермский государственный аграрно-технологический университет имени академика Д.Н. Прянишникова», г. Пермь
Plotnikov A.V. andreiplotnikovwork@gmail.com
КОНТЕНТ-АНАЛИЗ WEB-ДОКУМЕНТОВ СОГЛАСНО ПОИСКОВЫМ ЗАПРОСАМ
CONTENT ANALYSIS OF WEB-DOCUMENTS ACCORDING TO SEARCH QUERIES
Аннотация
В работе рассматривается метод обработки информации на естественном языке латентно-семантический анализ, анализирующий взаимосвязь между коллекцией документов и словами в них встречающимися. Анализ пользовательского запроса был произведен в системах Яндекс и Google. Рассмотрены показатели term frequency – показатель частоты или плотности вхождений термина в конкретном документе, а также показатель соотношения количества использования термина и суммарного числа слов в документе и inverse document frequency – обратная частота документа относительно запроса, то есть отношение всей подборки документов в поисковой базе к тем, что содержат в себе заданный термин.
Summary
The paper considers the method of processing information in natural language latent-semantic analysis, which analyzes the relationship between the collection of documents and the words they meet. The analysis of the user request was made in Yandex and Google systems. The term frequency parameters are considered — an indicator of the frequency or density of occurrences of a term in a specific document, as well as an indicator of the ratio between the use of the term and the total number of words in the document and the inverse document frequency — the inverse frequency of the document with respect to the query, that is the ratio of the entire collection of documents in the search database to those, that contain a given term.
Ключевые слова: латентно-семантический анализ, латентно-семантический индекс, поисковая оптимизация, поисковый маркетинг, контент-маркетинг.
Keywords: Latent-Semantic Analysis, Latent-Semantic Index, Search Engine Optimization, Search Engine Marketing, Content Marketing.
Введение
Уровень качества сайта определяется предельным соответствием контента ключевым фразам, по которым продвигается ресурс. Иными словами, их релевантность. Поисковые системы выдают информацию с помощью специальных алгоритмов, классифицирующих результат поиска по релевантности web-ресурсов по пользовательским запросам.
Chen C. M. [1] в своей статье доказывает, что латентное семантическое индексирование (LSI [2] [3]) (латентно-семантический анализ (LSA [4])), основанное на векторном пространстве является подходом к поиску информации и наиболее эффективным инструментом корреляции для получения соответствующих документов. Несмотря на то, что значительное число работ была посвящено LSI, большая часть из них рассматривает алгоритмическую или теоретическую основу модели. И лишь небольшое количество посвящено практическим проблемам внедрения. Система LSI интегрирует компоненты, включая сбор и предварительную обработку документов, декомпозицию сингулярных значений (SVD), многоязычную обработку и метод доступа на основе дерева запросов сходства. Chen C. M. определил проблемы внедрения, возникающие при разработке системы реализации. В частности, Chen C. M. рассматривает проблемы масштабируемости в механизмах запросов и различных компонентах системы. Bifet Figuerol A. C. [5] В своей статье исследует влияние различных функций страницы на ранжирование результатов поисковой системы. Автор использует Google (через API) и анализирует ранжирование результатов для нескольких запросов различных категорий с использованием статистических методов. Bifet Figuerol A. C. переформулирует проблему изучения лежащих в основе скрытых оценок как проблему двоичной классификации, применяя как линейные, так и нелинейные методы. Во всех случаях автор разделяет данные на обучающий набор и набор тестов, чтобы получить значимую, беспристрастную оценку качества предиктора. Результаты показывают, что скоринговая функция не может быть хорошо аппроксимирована с использованием только наблюдаемых признаков. Ryley J. F., Saffer J., Gibbs A. [6] отмечают, что LSI может использоваться в патентном поиске для преодоления недостатков булевого поиска и обеспечения более точного поиска. LSI сочетает в себе векторную пространственную модель (VSM) извлечения документов с разложением одного значения (SVD), используя линейные методы алгебры для выявления отношений слов в тексте. Результаты могут быть улучшены с помощью текстовой кластеризации и настройки параметров SVD для конкретного корпуса, в данном случае патентов, и с помощью методов устранения неоднозначностей в языке.
Контент–анализ
Анализ контента на страницах сайта позволяет web-мастеру или оптимизатору изучить плотность ключевых фраз в текстах, заголовках «Title», h1, h2, h3, мета-тегах, анкорах и провести оптимизацию страниц в соответствии с рекомендациями поисковых систем.
Нельзя забывать о том, что плотность ключевых слов играет существенную роль в ранжировании документа. При недостаточной плотности ключевых слов и отсутствии слов, задающих тематику, сайт будет на низких позициях. При превышающем проценте вхождений, сайт рискует быть отфильтрованным или вообще исключенным из индексации поисковых систем.
Анкор (привязка, якорь от англ. «anchor») – текстовое ядро, располагающееся между открывающим и закрывающим тегами <a>…. </a>. Любой сайт в Интернете связан с другими ресурсами огромной сетью ссылок, имеющих формат <a href =”адрес сайта”>текстовое ядро</a>. Именно анкор заключает в себе семантическое ядро, продвижение в соответствии с которым обеспечивает сайту ту или иную позицию в поисковых системах, и это есть один их основных факторов, влияющих на ссылочное ранжирование. Правильное выстраивание анкоров очень важно, что можно наблюдать на таком примере: в процессе поиска нужного сайта, Яндекс часто выдает ресурсы, в сниппете (описании) которых фигурирует «Найден по ссылке». То есть, вне зависимости от того, релевантна страница пользовательскому запросу или нет, она будет в выдаче результатов поиска, так как она релевантна ранжированию.
Разновидности анкоров
В соответствии с типом вхождения или написания классифицируют неразбавленные и разбавленные анкоры. Неразбавленные представляют собой неизменяемое ключевое слово, то есть точное вхождение семантического ядра, без дополнительных слов. Разбавленные, помимо ключевой фразы могут дополняться другими словами или выражениями.
Пример: для запроса «сыр филадельфия», неразбавленный анкор − «сыр филадельфия», а разбавленный – «сыр филадельфия своими руками», «приготовить сыр филадельфия дома».
Кроме того, анкоры подразделяются на высокочастотные, среднечастотные и низкочастотные – ВЧ (условно более 1000 запросов в месяц), СЧ (100-1000) и НЧ (до 100) соответственно, в зависимости от типов поисковых запросов и географии таргетинга.
- Высокочастотные, в основном, включают в себя одно или два слова, наиболее часто задаваемых пользователями в поисковиках. Согласно приведенному выше примеру, «сыр филадельфия» – это яркий образец высокочастотного анкора, отличающийся прямым или точным вхождением ключевой фразы, то есть неразбавленный.
- Среднечастотные содержат от двух до четырёх слов, как в примере «сыр филадельфия в домашних условиях» и представляют собой разбавленные анкоры для высокочастотных запросов.
- Для низкочастотных запросов, в которых больше четырех слов, выдают разбавленные высокочастотные и среднечастотные анкоры, например, «сливочный сыр филадельфия в домашних условиях рецепт».
Пассаж – это небольшие фрагменты текста, обособленные знаками препинания либо html –тегами. Поисковые машины разбивают текстовый контент страницы на пассажи и вычленяет слова или фразы, введенные в запросе. Если слова из запроса найдены и расположены близко друг к другу, машина классифицирует текст как релевантный запросу и страницу включает в ранжирование.
Алгоритм TF-IDF
Алгоритм TF-IDF – по этой формуле оценивается значимость определенного слова в документе относительно общей подборки в базе.
TF – term frequency – показатель частоты или плотности вхождений термина в конкретном документе, а также показатель соотношения количества использования термина и суммарного числа слов в документе, то есть частотность термина.

Эта статистическая формула упрощает поиск, выявляя важные или ключевые слова в документе, а также индексируя малозначимые и стоп-слова, имеющие низкое значение TF-IDF.[7]
Страница состоит из 2000 слов, из них 20 раз встречается слово «закон».
TF соответственно будет равен 20/2000 = 0.01.
Затем имеем количество страниц в интернете, к примеру, 8 000 000 000, и в 4 000 000 из них встречается слово «закон».
DF будет равен 4000000/8000000000 = 0.0005.
Вычисляем Вес слова TF/DF = 0.01/0,0005 = 20
Последовательность применения метода
- поисковой сервис выдаст топовые URL, по которым будет проведено сопоставление главных показателей;
- далее рассчитываются основные характеристики документа и относящиеся к нему блоки URL из Tоп-10: Title, анкоры, короткие пассажи.
- получаем среднестатистическую информацию по всем терминам, встречающимся у конкурентов. Подсчитаем и переведем в проценты вхождение каждого слова во всем документе и в его отдельных блоках.
- по результатам значений этой таблицы оформляется техническое задание и рекомендации для копирайтера.
- выдвигаются требования по количеству и точности вхождений в Title, в description, в заголовки второго и третьего уровня, в тело текста, по объему текста, пассажам и количеству ссылок.
- Если необходимо сравнить URL продвигаемый с топовыми в результатах выдачи поисковика (или собственным списком URL), добавьте его в это пространство;
- Определяем сопоставление по количеству знаков и слов в Title, пассажам, ссылкам и тексту;
- Теперь есть возможность оценить оптимизацию страницы под конкретный запрос и сформулировать рекомендации по всесторонней доработке;
В качестве ключевого запроса был взят запрос «сыр филадельфия в домашних условиях»
Первая часть анализа проводилась в поисковой системе Яндекс, по результатам органической выдачи, в качестве геопозиции – г. Москва.
Определен Топ-10 URL по запросу:
http://sovets.net/6548-syr-filadelfiya-v-domashnikh-usloviyakh.html
http://zhenskoe-mnenie.ru/themes/retsepty/syr-filadelfiia-v-domashnikh-usloviiakh-retsept-populiarnogo-produkta-varianty-prigotovleniia-syra-filadelfiia-v-domashnikh-usloviiakh/
http://notefood.ru/retsepty-blyud/salaty-i-zakuski/prigotovlenie-slivochnogo-syra-filadelfiya-v-domashnih-usloviyah.html
http://4vkusa.mirtesen.ru/blog/43812512739
http://anisima.ru/domashnyaya-filadelfiya/
http://gotovimsrazu.ru/zakuski/kak-prigotovit-syr-filadelfiya-v-domashnih-usloviyah.html
Таблица 1 – Сравнение общих показателей в Яндекс и Google
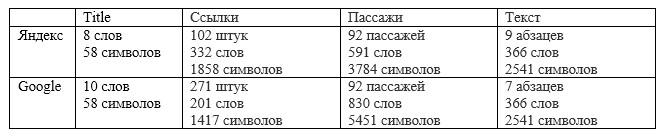
Таблица 2 – Детализированный результат анализа по органической выдаче в Яндекс
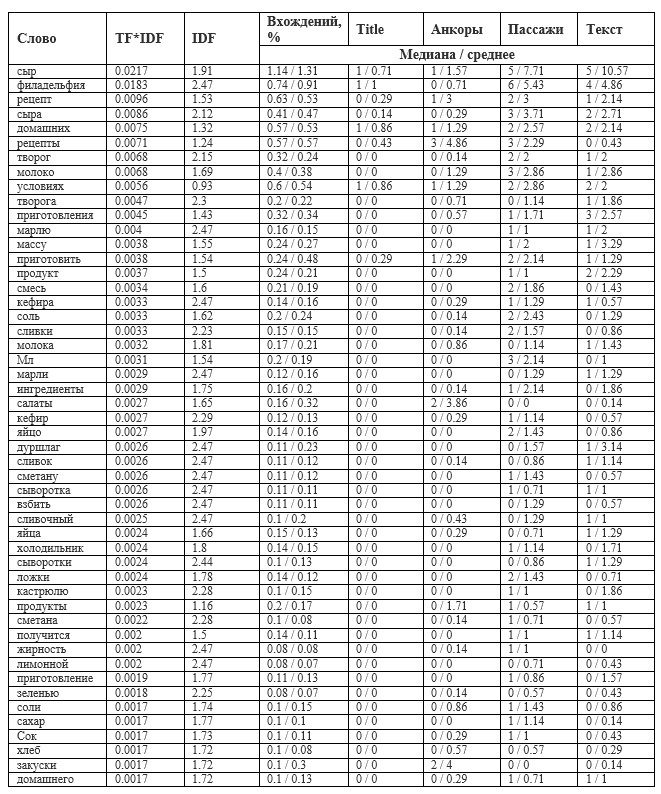
В качестве ключевого запроса был взят запрос «сыр филадельфия в домашних условиях»
Первая часть анализа проводилась в поисковой системе Google, по результатам органической выдачи, в качестве геопозиции – г. Москва.
Определен Топ-10 URL по запросу:
http://edimdoma.ru/retsepty/29864-gotovim-syr-filadelfiya-v-domashnih-usloviyah
http://edimdoma.ru/retsepty/29864-gotovim-syr-filadelfiya-v-domashnih-usloviyah
http://edimdoma.ru/retsepty/77872-syr-filadelfiya-v-domashnih-usloviyah
http://volshebnaya-eda.ru/kollekcia-receptov/snack/cold/filadelfiya/
http://notefood.ru/retsepty-blyud/salaty-i-zakuski/prigotovlenie-slivochnogo-syra-filadelfiya-v-domashnih-usloviyah.html
http://womanadvice.ru/syr-filadelfiya-v-domashnih-usloviyah
Таблица 3 – Детализированный результат анализа по органической выдаче в Google
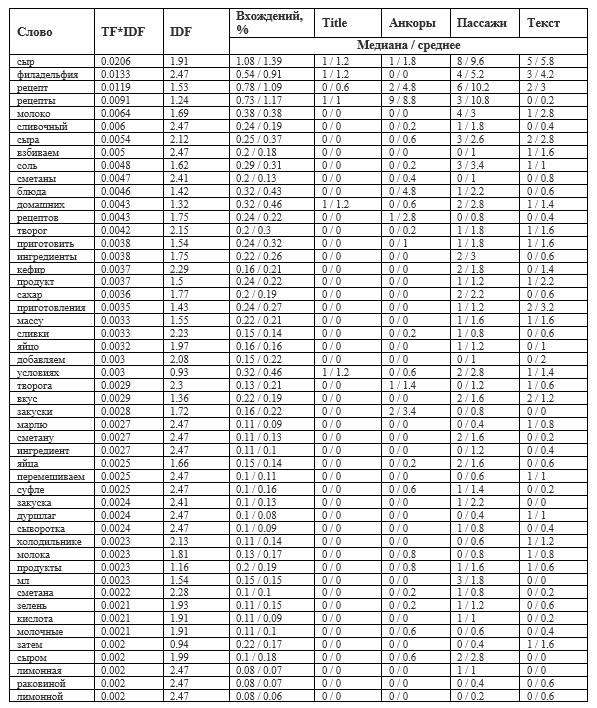
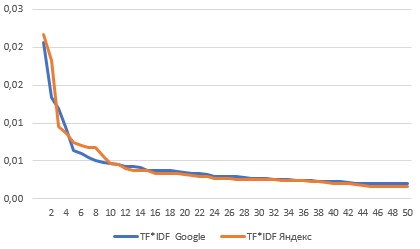
Рисунок 1. Сравнение TF*IDF Google и Яндекс
Рисунок 2. Сравнение IDF Google и Яндекс
Заключение
На основе семантического анализа можно определить слова, наиболее близкие по содержанию к общей теме документа согласно векторному пространству (молоко, сливочный, сыра, взбиваем, соль, сметаны, блюда, домашних, рецептов, творог, приготовить, ингредиенты и др.). Вероятно, что поисковые системы применяют множество методик для нахождения полезного контента или текстового мусора, или «спам» текста. Применение слов латентно-семантического индексирования даст оптимальный результат в совокупности с улучшением значений поведенческих метрик, которые также влияют на ранжирование документа в поисковой системе.
Список литературы
- Chen C. M. et al. Telcordia LSI engine: Implementation and scalability issues //Research Issues in Data Engineering, 2001. Proceedings. Eleventh International Workshop on. – IEEE, 2001. – С. 51-58.
- Что такое LSI или латентно-семантический индекс для лучшего понимания контекста страницы https://seoprofy.ua/blog/wiki/what-is-lsi-keywords
- Латентно-семантическое индексирование cropas.by/seo-slovar/lsi
- Латентно-семантический анализ https://dic.academic.ru/dic.nsf/ruwiki/595989
- Bifet Figuerol A. C. et al. An analysis of factors used in search engine ranking. – 2005.
- Ryley J. F., Saffer J., Gibbs A. Advanced document retrieval techniques for patent research //World Patent Information. – 2008. – Т. 30. – №. 3. – С. 238-243.
- Проверка TF-IDF https://ru.megaindex.com/support/faq/tf-idf