



УДК 004.9
DOI 10.24411/2413-046Х-2019-16034
Современные тенденции методов интеллектуального анализа данных: метод кластеризации
Current trends in data mining methods: clustering method
Махрусе Насма, аспирантка финансового университета при правительстве РФ, г.Москва.
Nasma Mahrouse, Postgraduate Student, Financial University under the Government of the Russian Federation, Moscow.
Аннотация:Цель этого исследования – предоставить исчерпывающий обзор современных различных методов кластеризации при извлечении данных и поиск алгоритмов кластеризации, а также провести сравнение между методами кластеризации и их алгоритмами. Наиболее важным в этом исследовании является обсуждение нескольких алгоритмов каждого метода кластеризации и показать любой алгоритм , подходящий для данного приложения больше , чем другие . любой из которых более чувствителен к шуму, чем другой. какие из них более способны справиться с выбросами. Это анализ помогает дать четкое представление о том, какой алгоритм или метод можно использовать для конкретного приложения. это также помогает выбрать, какие методы могут дать наилучшие результаты для конкретного приложения.
Summary:The purpose of this study is to provide a comprehensive overview of modern various clustering methods for data extraction and the search for clustering algorithms, as well as to make a comparison between clustering methods and their algorithms. The most important in this study is the discussion of several algorithms for each clustering method and to show any algorithm that is suitable for this application more than others. Any of which is more sensitive to noise than the other. Which ones are more able to cope with emissions. This analysis helps to give a clear idea of which algorithm or method can be used for a particular application. It also helps to choose which methods can give the best results for a particular application.
Ключевые слова: кластеризация; Иерархические; Грид-методы ; Методы разбиения; интеллектуальный анализ данных(ИАД) .
Key words: clustering; Hierarchical; Grid-based methods; partitioning method; Data mining.
Кластеризация – это процесс группировки множества физических или абстрактных объектов в похожие классы. Коллекция объектов данных, которые похожи друг на друга в одном кластере и отличаются от объектов в других кластерах, называется кластером. Кластеризация, также известная как кластерный анализ, стала важной техникой в машинном обучении, используемой для обнаружения естественной группировки наблюдаемых данных. Часто проводится четкое различие между проблемами обучения, которые контролируются, также известными как классификация, и теми, которые не контролируются, известными как кластеризация [1]. Кластеризацией также называется сегментация данных в некоторых приложениях, поскольку кластеризация разделяет большие наборы данных на группы в соответствии с их сходством. Кластеризация может также использоваться для обнаружения выбросов, где выбросы могут быть более интересными, чем обычные случаи. Целью кластеризации является уменьшение объема данных путем категоризации или группировки похожих элементов данных. Такая группировка широко распространена в том, как люди обрабатывают информацию, и одной из причин использования алгоритмов кластеризации является предоставление автоматизированных инструментов, помогающих строить категории или таксономии [Jardine and Sibson, 1971, Sneath and Sokal, 1973].
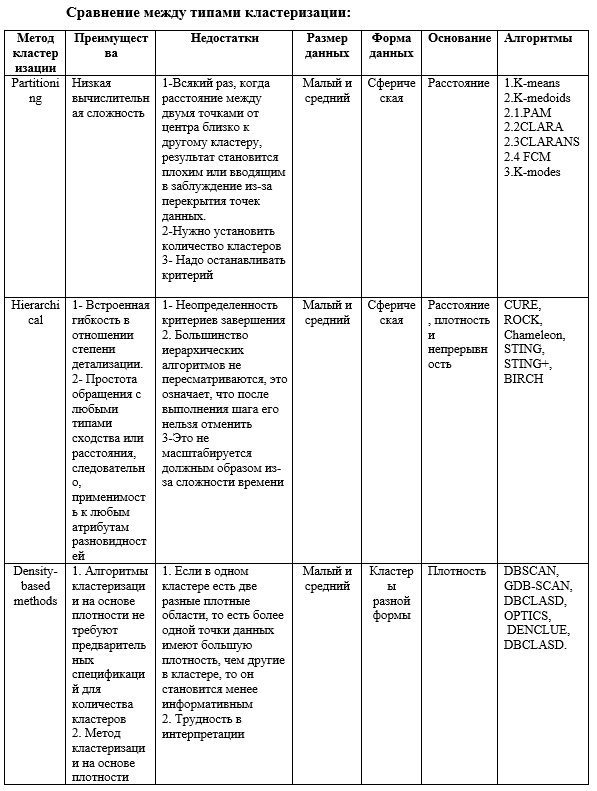
Методы кластеризации:
Трудно обеспечить четкую категоризацию методов кластеризации, поскольку эти категории могут перекрываться, так что метод может иметь функции из нескольких категорий. Методы кластеризации [Tryon and Bailey, 1973, Anderberg, 1973, Hartigan, 1975, 1988, Jardine and Sibson, 1971, Jain and Dubes, Sneath и Sokal, 1973] можно разделить на два основных типа: иерархическая и секционная кластеризация. Внутри каждого из типов существует множество подтипов и различных алгоритмов поиска кластеров.
Фахад и др. (2014) предложили классификацию кластеризации с точки зрения разработчика алгоритма. Он пытается разделить различные подходы к кластеризации на основе технических деталей каждого подхода, в результате чего получается дерево, показанное на рис. 1.
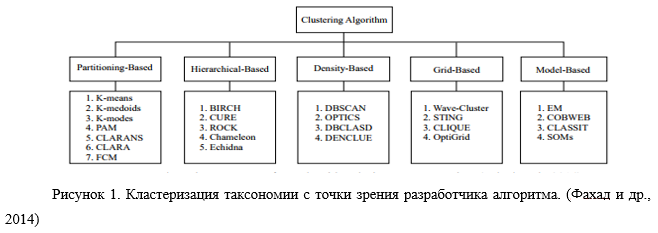
В целом, основные методы кластеризации можно классифицировать по следующим категориям.
- Методы разбиения: (Partitioning).
Основной целью алгоритма кластеризации разделов является разделение точек данных на K разделов. Каждый раздел будет отражать один кластер. Техника разбиения зависит от определенных целевых функций. Это означает, что он будет классифицировать данные по k группам, которые удовлетворяют двумя требованиям. Во-первых, каждая группа содержит хотя бы один объект. И, во-вторых, каждый объект должен принадлежать только одной группе.
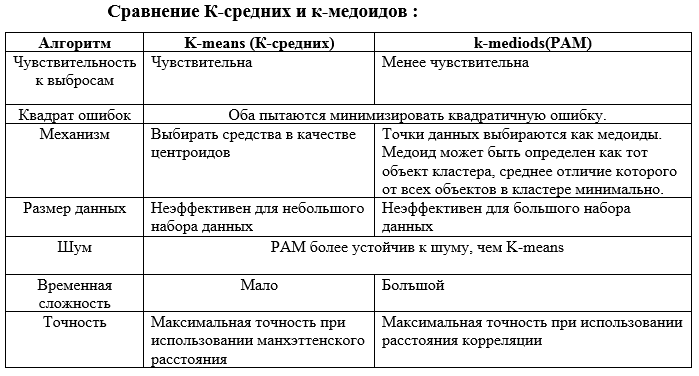
1- К-средних (K–means):
K-средних – это один из самых распространенных и простых алгоритмов обучения без контроля, которые используются для кластеризации. Кластеризация – это тип обучения без учителя [Crocker and Keller, 2003].
K-средних – это алгоритм интеллектуального анализа данных, который выполняет кластеризацию на заданном наборе данных. Как упоминалось ранее, кластеризация – это процесс, который делит набор данных на несколько кластеров, где каждый кластер содержит сходные данные (Kantabutra, 1999). Кластер определяется путем поиска по средним, чтобы найти кластер с ближайшим средним к объекту. Наименьшим удаленным средним считается среднее кластера, к которому принадлежит исследуемый объект (MacQueen, 1967). Есть много применений этого алгоритма: Поведенческая сегментация (Сегментация по истории покупок;Сегментация по действиям в приложении, веб-сайте или платформе;Создание профилей на основе мониторинга активности.); Классификация документов; Страхование: обнаружение страхового мошенничества; Телеком: детальный анализ записи разговоров; Сортировка датчиков измерений; Медицина: медицинская сегментация изображений; Здравоохранение (анализ DNA).
2- К-медоиды (K-medoids):
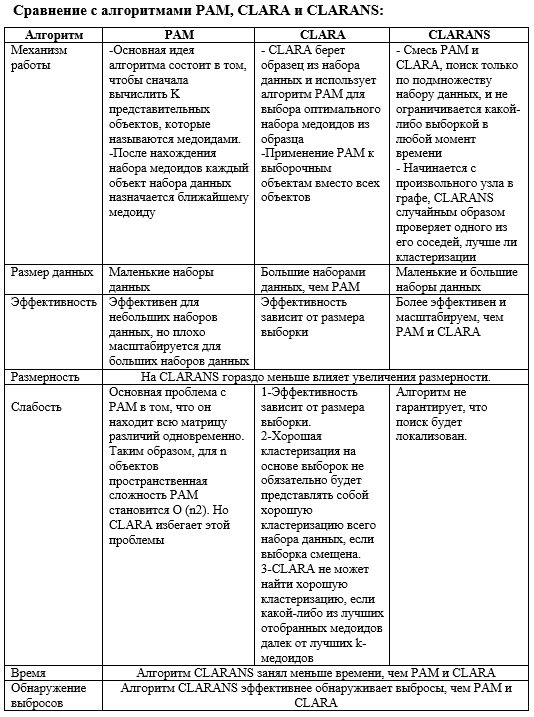
2.1. PAM (Partitioning Around Medoids 1987)
Алгоритм K-mediods(PAM), предложенный Kaufman и Rousseeuw (1987), является алгоритмом разбиения кластеров, который немного модифицирован по сравнению с алгоритмом K-средних. Они оба пытаются минимизировать квадратичную ошибку, но алгоритм K-medoids более устойчив к шуму, чем алгоритм K-средних.PAM, как известно, является наиболее мощным, однако PAM имеет недостаток, заключающийся в том, что он работает неэффективно для большого набора данных из-за его временной сложности (Han et al., 2001). Цель алгоритма – минимизировать среднее несоответствие объектов ближайшему выбранному объекту. Эквивалентно, мы можем минимизировать сумму различий между объектом и его ближайшим выбранным объектом. Алгоритм имеет две фазы: фаза сборки и фаза обмена. Вот несколько вариантов использования PAM: Здравоохранение; Обнаружение выбросов; категоризация объектов, анализ изображений, биоинформатика и сжатие данных; Кластеризация текстовых документов.
2.2. CLARA: (Clustering Large Applications 1990):
Этот алгоритм является развивающимся алгоритмом для кластеризации K-mediods. Kaufman и Rousseeuw (1990) также предложили алгоритм под названием CLARA (Clustering Large Applications), который применяет PAM к выборочным объектам вместо всех объектов. Он случайным образом выбирает данные и выбирает медоид, используя алгоритм PAM. Lucasius, Dane и Kateman (1993) сообщают, что производительность CLARA быстро падает ниже приемлемого уровня с увеличением количества кластеров. CLARA для обработки больших наборов данных была также предложена Kaufman и Rousseeuw [2]. По сравнению с PAM, CLARA может работать с гораздо большими наборами данных. Как и PAM, CLARA также находит объекты, расположенные в центре кластеров. Некоторые применения CLARA: Планирование; Обнаружение выбросов.
2.3. CLARANS ( Randomized” CLARA 1994):
Хан [3] предлагают другой вариант CLARA под названием CLARANS. Этот алгоритм пытается сделать поиск k репрезентативных объектов (медоидов) более эффективным, рассматривая наборы кандидатов из k медиод в окрестности текущего набора из k медоидов. Однако CLARANS не предназначен для реляционных данных. CLARANS начинается со случайно выбранного узла. Алгоритм CLARANS смешивает PAM и CLARA, выполняя поиск только в подмножестве набора данных, и он не ограничивается какой-либо выборкой в любой момент времени. Некоторые применения алгоритма CLARANS: Текстовая кластеризация; Обнаружение выбросов.
2.4. Нечеткие c-средних (FCM): (Fuzzy c-means)
Нечеткая кластеризация – мощный неконтролируемый метод анализа данных и построения моделей. Во многих ситуациях нечеткая кластеризация является более естественной, чем жесткая кластеризация.
FCM использует нечеткое разбиение, так что точка данных может принадлежать всем группам с различными уровнями участия от 0 до 1 [4]. Этот алгоритм работает, назначая место каждой точке данных, соответствующей каждому центру кластера, на основе расстояния между центром кластера и точкой данных. Чем больше данных находится рядом с центром кластера, тем больше его членство в конкретном центре кластера. Понятно, что сумма членства каждой точки данных должна быть равна единице. Некоторые применения алгоритма FCM: Сегментация медицинских изображений; Сегментация изображения; Сегментация видео; Цветовая сегментация; Сельскохозяйственное машиностроение, астрономия, химия, геология, анализ изображений, медицинская диагностика, анализ формы и распознавание целей.
2.5. K-режимы (K–modes):
Алгоритм кластеризации K-режимов основан на парадигме K-средних, но устраняет ограничение числовых данных, сохраняя при этом его эффективность. Алгоритм K-режимов расширяет парадигму K-средних для кластеризации категориальных данных, устраняя ограничения, налагаемые K-средними. Хуанг [5] также указывает, что в общем случае алгоритм K-мод быстрее, чем алгоритм K-средних, поскольку для его сходимости требуется меньше итераций. Хуанг [6] представляет алгоритм кластеризации K-modes, вводя новую меру различия в кластеризованных категориальных данных. Алгоритм заменяет средства кластеров на режимы (наиболее частое значение атрибута в атрибуте) и использует частотный метод для обновления режимов в процессе кластеризации, чтобы минимизировать функцию стоимости.
- Иерархические методы:
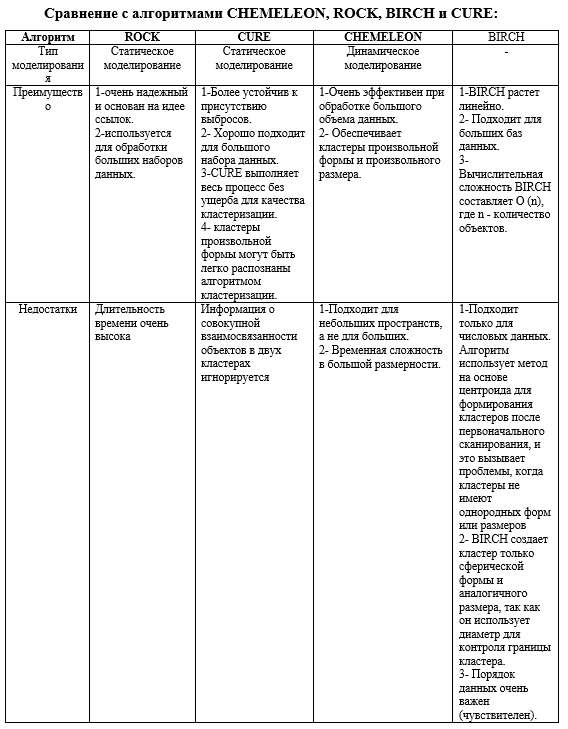
Метод иерархической кластеризации работает путем группировки объектов данных в дерево кластеров. Существует два типа методов иерархической кластеризации: агломеративная иерархическая и дивизионная кластеризации [7]. Агломеративный: в агломерационном подходе изначально один объект выбирается и последовательно сливается (агломерат) с ближайшей подобной парой на основе критериев сходства, пока все данные не образуют желаемый кластер.
- CURE (Clustering Using representatives):
CURE – это алгоритм агломерационной иерархической кластеризации, который создает баланс между центроидом и всеми точечными подходами. Судипто Гуха и др. предложили новый алгоритм иерархической кластеризации, названный CURE, который сильнее к выбросам, и идентифицирует кластеры, имеющие несферическую форму и большие различия в размере. По сути, CURE – это алгоритм иерархической кластеризации, который использует разбиение набора данных. В этом процессе случайная выборка, взятая из набора данных, сначала разделяется, а затем каждый раздел частично кластеризуется. Частичные кластеры затем снова группируются во второй проход, чтобы получить желаемые кластеры. Экспериментально подтверждено, что качество кластеров, созданных CURE, намного лучше, чем у других существующих алгоритмов [8].
- ROCK (Robust Clustering using links)
ROCK – это надежный алгоритм агломерационной иерархической кластеризации, основанный на понятии связей. Это также подходит для обработки больших наборов данных. Для объединения точек данных ROCK использует связи между точками данных, а не расстояние между ними. Алгоритм ROCK наиболее подходит для кластеризации данных, которые имеют логические и категориальные атрибуты. В этом алгоритме сходство кластеров основано на количестве точек из разных кластеров, имеющих общих соседей. ROCK не только генерирует кластер лучшего качества, чем традиционный алгоритм, но также демонстрирует хорошие свойства масштабируемости [8].
- CHEMELEON (hierarchical clustering using dynamic modeling):
CHEMELEON – это алгоритм агломерационной иерархической кластеризации, использующий динамическое моделирование. Это иерархический алгоритм, который измеряет сходство двух кластеров на основе динамической модели. Процесс слияния с использованием динамической модели облегчает обнаружение естественных и однородных кластеров. Методология динамического моделирования кластеров, которая используется в CHEMELEON, применима ко всем типам данных, если можно построить матрицу подобия. Процесс алгоритма в основном состоит из двух этапов: сначала выполняется разбиение точек данных для формирования подкластеров с использованием разбиения графа, после чего приходится многократно объединять подкластеры, которые приходят с предыдущего этапа, чтобы получить окончательные кластеры. Доказано, что алгоритм находит кластеры различных форм, плотностей и размеров в двумерном пространстве. CHEMELEON – это эффективный алгоритм, который использует динамическую модель для получения кластеров произвольной формы и произвольной плотности [9].
- BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies:
Тянь Чжан и др. предложили метод агломерационной иерархической кластеризации под названием BIRCH и подтвердили, что он особенно подходит для больших баз данных. BIRCH был также первым алгоритмом кластеризации, предложенным в области базы данных, который может эффективно обрабатывать шум. BIRCH – это алгоритм агломерационной иерархической кластеризации, особенно подходящий для очень больших баз данных. Этот метод был разработан таким образом, чтобы минимизировать количество операций ввода-вывода. Процесс BIRCH начинается с иерархического разделения объектов с использованием древовидной структуры, а затем применяется другие алгоритмы кластеризации для уточнения кластеров. Он постепенно и динамически группирует входящие точки данных и пытается произвести кластеризацию наилучшего качества с доступными ресурсами, такими как доступная память и временные ограничения.
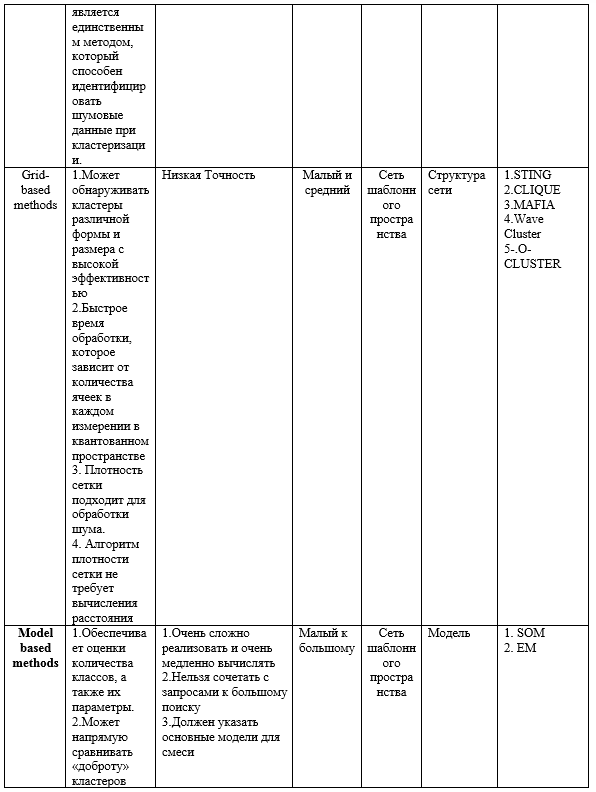
- Методы, основанные на плотности.
Понятие кластеризации на основе плотности было исследовано Jain and Dubes (1988) в том, что они называют кластеризацией с помощью оценки плотности и режим поиска. В их подходе области высокой плотности называются модами. Каждый режим соответствует центру кластера, а векторы данных назначаются кластеру, центр которого находится ближе всего к ним.
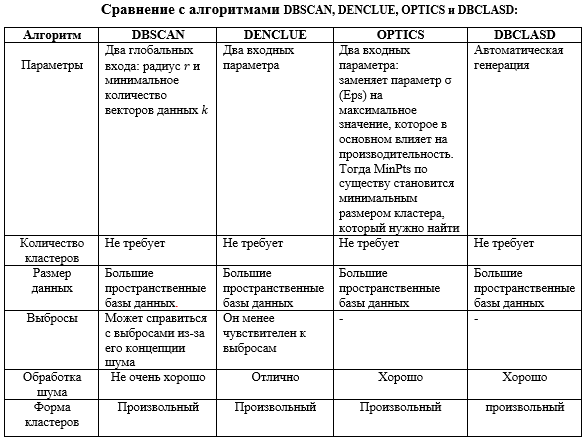
Этот метод кластеризации часто используется для поиска кластерных данных о точках, образованных естественными структурами, такими как дороги, вулканы и реки. При использовании для «естественного» применения они называются «естественными кластерами» [10]. Методы на основе плотности связаны с обучающей точкой данных, и DBSCAN и DBCLASD подпадают под это, в то время как функции плотности связаны с точками данных для вычисления функций плотности, определенных в базовом пространстве атрибутов, а DENCLUE [10] подпадает под это. DBCLASD, OPTICS DBSCAN – это алгоритмы кластеризации на основе плотности. [10]
Обзор алгоритмов кластеризации на основе плотности:
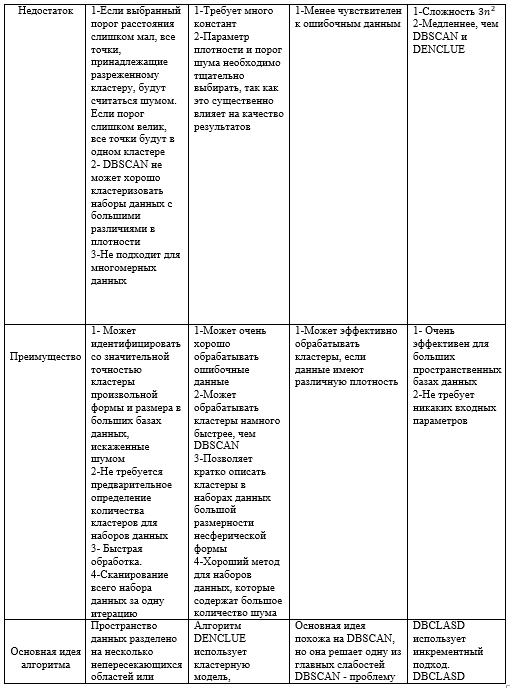
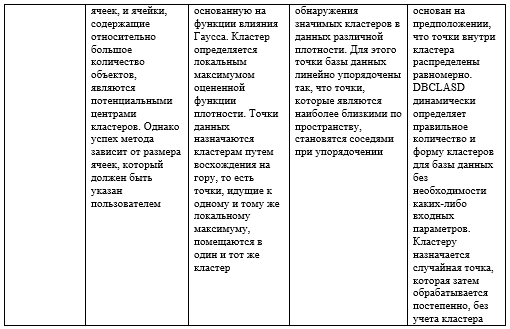
- DBSCAN (Density-Based Spatial Clustering Application with Noise)
DBSCAN [11] Это кластеризация секционного типа, где более плотные области рассматриваются как кластеры, а области низкой плотности называются шумом. Ester и др. (1996) представили наиболее известный алгоритм кластеризации на основе плотности – пространственную кластеризацию на основе плотности приложений с шумом (DBSCAN). DBSCAN превосходит алгоритмы иерархии и разделения. Тем не менее, зависит от размерности данных, которая была у Kotsiantis & Pintelas (2004). DBSCAN не требует, чтобы число кластеров было задано в качестве параметра из-за способа формирования кластеров на основе возможности соединения векторов данных друг с другом. DBSCAN [12] считается одним из самых мощных и наиболее цитируемых алгоритмов кластеризации на основе плотности, который может со значительной точностью идентифицировать кластеры произвольной формы и размера в больших базах данных, искаженных шумом.. Некоторые применения алгоритма DBSCAN: Электронная коммерция; Здравоохранение (анализ DNA); Обнаружение аномалий в данных о температуре; Телекоммуникации (понимание поведения клиентов); Торговые площади (прогноз движения человека); Социальные сети; Графика (видео абстракция).
- Плотность на основе кластеризации (DENCLUE).
DENCLUE [10] Здесь используются основные понятия, то есть функции влияния и плотности. Влияние каждой точки данных можно моделировать как математическую функцию, а результирующая функция называется функцией влияния. Это алгоритм кластеризации, который зависит от функций плотности, вытекающей из функции влияния Гаусса.
Кластер определяется локальным максимумом оцененной функции плотности. Точки данных присваиваются кластерам путем набора высоты, то есть точки, идущие к одному и тому же локальному максимуму, помещаются в один и тот же кластер. В подходе Александр Хиннебург и др. предложил новый алгоритм кластеризации в базах данных, который состоит из большой мультимедийной информации, то есть называется DENCLUE, которая может обрабатывать шум. Некоторые применения алгоритма DENCLUE: Атмосферное пространство (автоматическое обнаружение галактики); Графика (видео абстракция); Сегментация изображения; Медицина (рак молочной железы: выявить гетерогенные клеточные субпопуляции).
- OPTICS (Ordering Points to Identify Clustering Structure)
Это один из методов кластеризации на основе плотности, который идентифицирует неявную кластеризацию в данном наборе данных. OPTICS может рассматриваться как обобщение DBSCAN, которое заменяет параметр σ (Eps) максимальным значением, которое в основном влияет на производительность. Тогда MinPts по существу становится минимальным размером кластера, который нужно найти. OPTICS не является алгоритмом кластеризации; скорее, это способствует идентификации структуры кластеризации путем упорядочения точек и расстояний достижимости таким образом, который может быть использован алгоритмом на основе плотности. Он расширяет DBSCAN для получения порядка кластеров, полученного из широкого диапазона настроек параметров. Как и DBSCAN и DENCLUE, он рассматривает плотность как региональное явление. Некоторые применения алгоритма OPTICS: Электронная коммерция; Атомно-зондовая Томография.
- DBCLASD (Distribution based clustering of large spatial databases)
DBCLASD использует инкрементный подход. DBCLASD основан на предположении, что точки внутри кластера распределены равномерно. DBCLASD динамически определяет правильное количество и форму кластеров для базы данных без необходимости каких-либо входных параметров. Кластеру назначается случайная точка, которая затем обрабатывается постепенно, без учета кластера. Алгоритм DBCLASD [13] обнаруживает кластеры произвольной формы и не требует никаких входных параметров. Эффективность DBCLASD для больших пространственных баз данных также очень привлекательна.
Алгоритм DBCLASD [14] основан на предположении, что точки внутри кластера распределены равномерно. Применение DBCLASD к каталогам землетрясений показывает, что он также эффективно работает в реальных базах данных, где данные распределены не совсем равномерно.
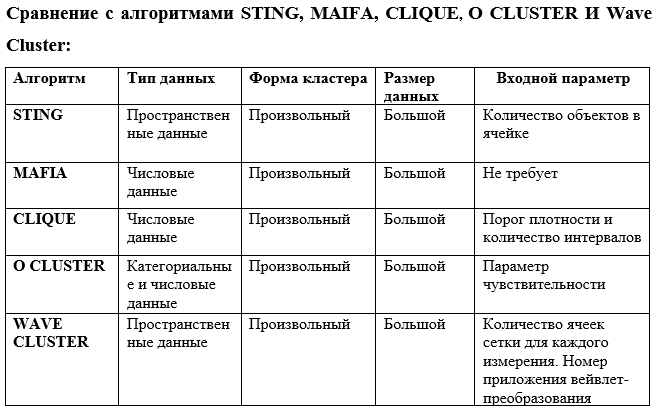
- Грид-методы.
Алгоритм на основе сетки определяет набор ячеек сетки, он назначает объекты соответствующей ячейке сетки и вычисляет плотность каждой ячейки, а также исключает ячейки, плотность которых ниже определенного порога t. Алгоритм на основе сетки использует сетку данных с высоким разрешением. Сложность кластеризации зависит от количества заполненных ячеек сетки, а не от количества объектов в наборе данных.
Методы на основе сетки работают в объектном пространстве, а не данные делятся на сетку. Разделение сетки основано на характеристиках данных, и такие методы могут легче обрабатывать нечисловые данные. Методы на основе сетки не зависят от порядка данных. Метод кластеризации на основе сетки отличается от традиционных алгоритмов кластеризации тем, что он касается не точек данных, а пространства значений, которое окружает точки данных. Алгоритмы кластеризации на основе сетки имеют преимущества обнаружения кластеров различной формы и размера с высокой эффективностью.
- STING Algorithm (A Statistical Information Grid Approach)
Ван и др. предложили метод статистической информации на основе сетки для анализа пространственных данных. В алгоритме STING пространственная область делится на прямоугольные ячейки. Существует несколько разных уровней таких прямоугольных ячеек, соответствующих разному разрешению, и эти ячейки образуют иерархическую структуру. Каждая ячейка на высоком уровне делится на несколько ячеек следующего более низкого уровня. Статистическая информация о каждой ячейке рассчитывается и сохраняется заранее и используется для ответа на запросы [15]. STING – это метод кластеризации на основе сетки с множественным разрешением, в котором пространственная область делится на прямоугольные ячейки (с использованием широты и долготы) и использует иерархическую структуру.
- CLIQUE (Clustering In Quest)
CLIQUE – это алгоритм кластеризации восходящего подпространства, который создает статические сетки. Он использует априорный подход, чтобы уменьшить пространство поиска. CLIQUE оперирует многомерными данными, обрабатывая не все измерения одновременно, а обрабатывая одно измерение на первом шаге, а затем увеличивая его до более высокого [16]. CLIQUE представляет собой алгоритм кластеризации на основе плотности и сетки, то есть обнаруживает кластеры, принимая порог плотности и количество сеток в качестве входных параметров. CLIQUE также может найти любое количество кластеров в любом количестве измерений, и это число не определяется параметром.
- MAFIA (Merging of Adaptive Intervals Approach to Spatial Data Mining)
Большинство алгоритмов, основанных на сетке, используют однородные сетки, тогда как MAFIA использует адаптивные сетки. MAFIA предлагает адаптивные сетки для быстрой подпространственной кластеризации и представляет масштабируемую параллельную структуру на архитектуре без совместного использования ресурсов для обработки массивных наборов данных [17]. MAFIA предлагает метод адаптивного вычисления конечных интервалов (бинов) в каждом измерении, которые объединяются для изучения кластеров в более высоких измерениях. MAFIA вводит параллелизм для получения хорошо масштабируемого алгоритма кластеризации для больших наборов данных.
- Волновой Кластер (Wave Cluster)
Wave Cluster, основанный на сетке, очень эффективен, особенно для очень больших баз данных. Wave Cluster – это алгоритм кластеризации с высоким разрешением. Волновой кластер хорошо способен находить кластеры произвольной формы со сложными структурами, такими как вогнутые или вложенные кластеры в разных масштабах, и не принимает какой-либо конкретной формы для кластеров. Сначала он суммирует данные путем наложения многомерной структуры сетки на пространство данных. Основная идея состоит в том, что вначале необходимо преобразовать исходный элемент с помощью вейвлет-преобразования, а затем найти плотные области в новом пространстве. Вейвлет-преобразование – это метод обработки сигнала, который разбивает сигнал на различные частотные поддиапазоны. Волновой кластер представляет собой кластерный подход, основанный на вейвлет-преобразованиях (Gholamhosein Sheikholeslami, Surojit Chatterjee, Aidong Zhang, 2000).
- O-CLUSTER (Orthogonal partitioning Clustering)/
O- кластер – непараметрический алгоритм. O-кластер оптимально функционирует для больших наборов данных с большим количеством записей и высокой размерностью. Этот метод кластеризации сочетает в себе новый метод активного разделения выборки с параллельной осевой стратегией для определения непрерывных областей высокой плотности во входном пространстве. O-кластер – это метод, основанный на концепции проецирования по контракту, представленной OPTIGRID.
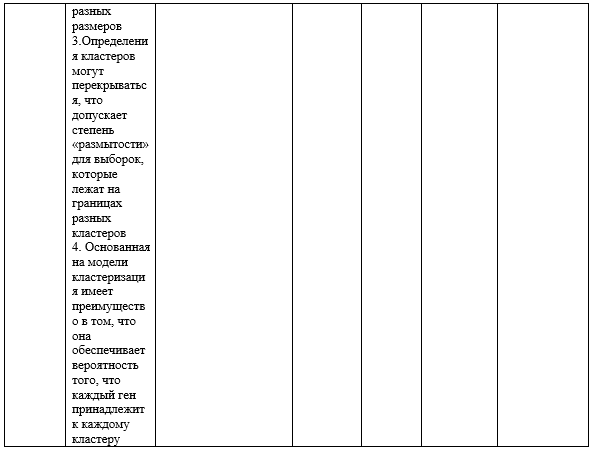
- Методы, основанные на моделях
Слово модель обычно используется для представления типа ограничений и геометрических свойств ковариационных матриц (Martinez and Martinez, 2005). В семействе алгоритмов кластеризации на основе моделей используются определенные модели для кластеров и делается попытка оптимизировать соответствие между данными и моделями. Кластеризация на основе моделей может помочь в применении кластерного анализа, требуя от аналитика сформулировать вероятностную модель, которая используется для подгонки данных, и, таким образом, сделать цели и формы кластеров более понятными, чем в случае эвристической кластеризации.
- SOM (Self-Organizing map) (Самоорганизующаяся карта)
Самоорганизующаяся карта (SOM) – это алгоритм обучения без присмотра, представленный Кохоненом. SOM может преобразовывать многомерные данные в двумерное представление и может включать автоматическую кластеризацию текстовых документов, сохраняя топологию более высокого порядка. Самоорганизующаяся карта (SOM) – это модель нейронной сети для визуализации и кластеризации данных. Последовательные и пакетные алгоритмы обучения SOM, предложенные Кохоненом, оказались успешными во многих практических приложениях. Однако они также страдают от некоторых недостатков, таких как отсутствие целевой (стоимостной) функции, общее доказательство сходимости и вероятностная структура. Некоторые применения алгоритма SOM: Распознавание речи; Бизнес-приложения (сегментация клиентов); Медицинская визуализация и анализ; Кластеризация текста; Робототехника; Классификация спутниковых изображений; Изучение музыкальных коллекций.
- EM ( Expectation–Maximization)
Алгоритм EM является итеративным, состоящим из двух чередующихся шагов: шаг Ожидание (E) и шаг Максимизация (M). EM требует накопления дробной статистики. Алгоритм EM имеет много преимуществ: простота, стабильность и устойчивость к шуму. Существует два основных применения алгоритма EM. Первое происходит тогда, когда данные действительно имеют пропущенные значения из-за проблем или ограничений процесса наблюдения. Второе происходит когда оптимизация функции правдоподобия аналитически неразрешима, но ее упростить, предполагая наличие и значения дополнительных, но отсутствующих (или скрытых) параметров.
Заключение:
Кластерный анализ широко используется во многих приложениях, включая исследования рынка, распознавание образов, анализ данных и обработку изображений. В бизнесе кластеризация может помочь маркетологам обнаружить отдельные группы в своих клиентских базах и охарактеризовать группы клиентов на основе моделей покупок.
ИАД включает в себя множество различных алгоритмов для решения различных задач. Все эти алгоритмы пытаются подогнать модель к данным. Алгоритмы проверяют данные и определяют модель, наиболее близкую к характеристикам исследуемых данных.
Литературы
- Han J., Pei J., Kamber M., Data Mining: Concepts and Techniques //Elsevier, New York, 2011.-P1-740.
- Kaufman L., Rousseeuw P. J Finding Groups in Data, An introducrion to Cluster Analysis // John Wiley & Sons, Brussels, Belgium, 1990. -P.1-355.
- Khan S., Rahman S.M. M., Tanim M. F. , Ahmed F. Factors influencing K means algorithm // Int. J. Computational Systems Engineering,2013 .- Vol. 1. -No. 4.-P 217-228.
- Chuang K. ,Tzeng H., Chen SH., Wu J. ,Chen T. Fuzzy c-means clustering with spatial information for image segmentation // Computerized Medical Imaging and Graphics 30 ,2006. -P. 9–15.
- Kaur P., Aggrwal S. Comparative Study of Clustering Techniques // international journal for advance research in engineering and technology, 2013.-P.1-4.
- Huang Z. Extensions to the k-means algorithm for clustering large data sets with categorical values, 1998. -P.283–304.
- Guha S., Rastogi R., Shim K. CURE: An Efficient Clustering Algorithm for Large data base 1998. – P. 1-12.
- . Databases, In Proc. ACM-SIGMOD lnt. Conference on Management of Data, 1998. -P.85-93.
- Yang J., Muntz R. STING: A statistical information grid approach to spatial data mining // Proc. 23rd Int. conf. on very large data bases. Morgan Kaufmann, 1997.-P.186-195.
- Ester M. Kriegel H.-P., Xu X. Knowledge Discovery in Large Spatial Databases: Focusing Techniques for efficient Class Identification // Proc. 4th Int. Symp. on large Spatial Databases, Portland, 1995. -Vol. 951.-P. 67-82.
- Ester M., et al.A density-based algorithm for discovering clusters in large spatial databases with noise // in Kdd, 1996. -P. 226-231.
- Kużelewska U. Clustering Algorithms in Hybrid Recommender System on MovieLens Data //STUDIES IN LOGIC, GRAMMAR AND RHETORIC 37 (50), 2014.-P.125-139.
- Wang W., Yang J., Muntz R. STING : A Statistical Grid Appraoch to Spatial Data Mining // Department of Computer Science, University of California, Los Angels,1997.-P.186-195.
- Xu X., Ester M., Kriegal H., Sabder J.A Distribution Based Clustering Algorithm for Mining in Large Spatial Databases, 1998.-P.1-8.
- Agrawal R., Gehrke J., Gunopulos D., Raghavan P. Automatic Subspace Clustering of High Dimensional Data. Data Mining and knowledge discovery //Springer Science + Business media, Inc. Manufactured in the Netherlands, 2005.-P.5-33.
- Goil S., Nagesh H., Choudhary A.MAFIA: Efficient and Scalable Clustering for very large data sets// Center for Parallel and distributed Computing, 1999.-P.1-20.
- Agrawal R., Gehrke J., Gunopulos D., Raghavan P. Automatic subspace clustering of high dimensional data for data mining applications // ACM SIGMOD inter- national conference on Management of data, June 1998. -Vol.27. – No.2.-P.94-105.