Московский экономический журнал 10/2019

УДК 004.738.52
DOI 10.24411/2413-046Х-2019-10078
ПРОБЛЕМЫ И РЕШЕНИЯ
ТЕХНОЛОГИИ СИСТЕМЫ ИЗБИРАТЕЛЬНОГО РАСПРОСТРАНЕНИЯ ИНФОРМАЦИИ (ИРИ) ИЗ ВНЕШНИХ
БАЗ ДАННЫХ
PROBLEMS AND SOLUTIONS OF SELECTIVE DISSEMINATION OF INFORMATION (SDI)
TECHNOLOGY FROM EXTERNAL DATABASES
Комаров Павел
Анатольевич, инженер-программист, Федеральное государственное бюджетное
научное учреждение «Центральная научная сельскохозяйственная библиотека» (ФГБНУ
ЦНСХБ), 107140,
Москва, Орликов пер., 3Б, E-mail: kpa@cshb.ru
Komarov P.A., software engineer, Federal State Budgetary Scientific
Institution “Central Scientific Agricultural Library”, Orlikov per., 3B,
Moscow, Russia, ZIP 107140, E-mail: kpa@cshb.ru
Аннотация: Современный
пользователь все больше привыкает к тому, что информация из различных
источников удобно доступна в одном месте, например в социальной сети. Поэтому,
чтобы сохранить и быть более привлекательной для своих читателей, библиотека
должна предоставлять им сервисы, основываясь не только на своих собственных, но
и на основе внешних баз данных. Работа с собственными базами данных радикально
отличается от работы с внешними, для которых чаще всего доступны лишь средства,
предусмотренные их разработчиками для обычных пользователей. Можно условно
выделить следующие подходы к реализации поиска по внешним базам данных: cоздание локальной копии базы
данных, поиск посредством инструментов для обычных пользователей, поиск через
API для разработчиков и использование функционала информирования самого источника.
В любом варианте чаще всего необходимо проведение обратной разработки системы
поиска каждой конкретной базы данных, определение возвращаемых полей и их
значений, выявление существующих технических ограничений и разработка схемы
внутренней базы данных для хранения полученной информации. Обязательно наличие
системы мониторинга, протоколирующей возникающие ошибки и прочие ситуации,
которые могут свидетельствовать о некорректной работе системы и извещающей о
них администратора.
Summary: A modern user is increasingly
getting used to the fact that information from various sources is conveniently
available in one place, on a social network, for example. Therefore, in order
to keep and be more attractive to its readers, the library must provide them
not only information from its own databases, but also from external ones.
Working with internal databases is radically different from working with
external ones, for which only the tools provided by their developers for
ordinary users are most often available. We can conditionally distinguish the
following approaches to the implementation of searches from external databases:
creating a local copy of the database, searching through tools for ordinary
users, searching through the API for developers, and using the notification
functionality of the database. In any case, most often it is necessary to carry
out the reverse development of the search system for each specific database, to
determine the returned fields and their values, to identify existing technical
limitations and to develop an internal database scheme for storing the received
information. Creating a monitoring system that logs errors and other situations
that may indicate malfunction of the system and notifies the administrator
about them is mandatory.
Ключевые
слова: избирательное распространение информации, ИРИ, информационные
ресурсы; информационное обслуживание; информационное обеспечение; научные
учреждения; интернет-ресурсы; АПК; ЦНСХБ.
Keywords: selective dissemination of
information, SDI, information resources; information service; information
support; scientific institutions; Internet-resources; Agro-Industrial
Complex; CSAL
Введение. В
современном мире нас окружает огромное количество информации, намного больше,
чем каждый из нас способен переработать в единицу времени. Поэтому мы вынуждены
чуть ли не ежесекундно фильтровать ее, не ознакомившись с ней даже бегло. И чем
больше информации один источник способен предоставить удобно в одном месте, тем
больше вероятность, что мы будем пользоваться именно им.
Социальные сети — это универсальный источник обмена
информацией, потому они вытесняют все остальные медиа. Получить
определенное количество информации в день сегодня можно в рамках одной вкладки
социальной сети. Сообщества в них вытеснили форумы по интересам за счет более
удобного интерфейса. Паблики газет и журналов, в целом, ничем не уступают их
отдельным и, тем более, печатным версиям, во многом они даже удобнее, поскольку
оставлять комментарии там проще.
Аналогичная ситуация складывается и в библиотечной сфере: библиотеки,
полнотекстовые, реферативные и наукометрические базы данных каждая имеет свою
поисковую систему, но пользователю просто неудобно последовательно переходить и
искать поочередно в каждой из них, и удобно, когда одна точка доступа дает его
сразу ко множеству источников.
Научные работники должны следить за новой информацией в
своей сфере, быть на острие прогресса, а времени на регулярный самостоятельный
поиск чаще всего не хватает, здесь на помощь им приходит система избирательного
распространения информации (ИРИ), которая периодически самостоятельно оповещает
читателя о новых публикациях по выбранной им тематике. Естественно, читателю
будет удобно, если такое оповещение будет осуществляться не только по фонду
библиотеки, но и по как можно большему количеству источников. Наличие такой
возможности повысит информационную привлекательность библиотеки в глазах
читателя. Системе ИРИ уделяют внимание многие библиотеки, в частности
Библиотека по естественным наукам Российской академии наук (БЕН РАН), что нашло
свое отражение во множестве их публикаций по данной тематике[1-4].
Федеральное государственное бюджетное научное учреждение
«Центральная научная сельскохозяйственная библиотека» (ЦНСХБ) как научная библиотека собирает и
предоставляет пользователям всю доступную информацию (печатные издания, аудио и
видео издания и т.п.) по сельскому хозяйству, делая упор на научный аспект и
прикладное применение научных достижений. На их основе
ЦНСХБ создает разнообразные электронные информационные ресурсы
собственной генерации, которые
составляют информационное обеспечение
АПК вместе с информацией из других источников по проблематике сельского
хозяйства, в том числе из других
библиотек АПК, формируя, таким образом, единое информационное пространство
отрасли. Поэтому в ЦНСХБ разрабатываются методы, программные решения и
технологии формирования распределенных информационных систем на базе облачных
вычислений по проблематике АПК [5-6]. В
ЦНСХБ уже разработана система оповещения
пользователя о новых поступления в базу
данных «АГРОС» — основной информационный продукт библиотеки – документов по
теме, заранее заявленной им. В 2019 г. проведены
исследования и разработана технология оповещения о поступлениях во внешние базы
данных по проблематике АПК.
Целью исследования
было разработка и совершенствование информационного обеспечения научных исследований по проблематике АПК.
Задача исследования
— разработка программных средств поддержки технологии сетевой распределенной системы
оповещения пользователей о поступлении документов во внешние базы данных по
аграрной тематике.
Актуальность темы исследования состоит в том, что
разработка технологии позволит повысить качество информирования пользователя,
получать информацию из внешних, в т.ч. зарубежных информационных ресурсов на
рабочий стол.
Научная новизна
исследования. В Централизованной электронной библиотечной системе АПК
(ЦЭБС) функционирует технология оповещения
пользователей по предварительно
сделанному тематическому запросу из информационных ресурсов собственной
генерации, в результате исследования создана технология, позволяющая получать информацию о новых
поступлениях во внешние базы данных .
Результаты
исследований и разработка технологии.
Выявляли и анализировали существующие технологии оповещения
ИРИ пользователей в отечественных и зарубежных информационных системах и
базах данных. Исследование выявило, что работа с внешними базами данных (БД)
радикально отличается от работы с собственными. Если для последних доступны все
возможности используемой СУБД, хорошо известна схема БД, то для внешних БД чаще
всего доступны лишь средства, которые их разработчик предусмотрел для обычных
пользователей, реже специальные API
для программистов. В любом случае, возможности эти очень сильно ограничены.
Подход к реализации поиска по внешним базам данных может
очень сильно различаться в зависимости от конкретного источника. Можно условно
выделить следующие:
- Создание локальной копии базы данных
- Поиск посредством инструментов для обычных
пользователей - Поиск через API для разработчиков
- Использование функционала информирования самого
источника
Очевидно, что с данными, хранящимися внутри собственной IT-инфраструктуры, намного
проще работать. Для них можно выполнить любой необходимый SQL-запрос, использовать уже имеющиеся
отработанные механизмы поиска, статистики или аналитики. Именно поэтому
создание локальной копии требуемой БД имеет значительное преимущество перед
другими подходами.
Идеальным вариантом является ситуация, когда владелец БД
согласен предоставлять ее копию через какие-либо промежутки времени. Поскольку
ведение любой БД связано со значительными затратами, то любая информация имеет
цену, и ее владелец не заинтересован в передаче ее другим лицам. Поэтому для
получения копии БД приходится использовать механизмы, доступные обычным
пользователям. Приемлем также вариант, когда
имеется регулярный доступ к БД, а в самой БД функционирует готовый механизм
оповещения.
Полнотекстовые, реферативные и наукометрические базы данных,
которые могут быть интересны нашим читателям, обязательно имеют поиск через
Интернет. В процессе анализа поисковых систем конкретной БД изучались:
- Механизмы авторизации пользователя на сайте в
случае отсутствия поиска в свободном доступе; - URL точек доступа к механизму поиска;
- HTTP-заголовки
авторизации; - Количество, имена, возможные значения, и формат
передачи параметров поиска; - Формат (например XML, JSON) возвращаемых результатов, их внутренняя структура;
- Ограничения сервера, связанные с защитой от
автоматизированных запросов, такие как ограничение количества запросов в
единицу времени с определенного IP-адреса
или пользовательской сессии.
Помимо этих, в некоторых
БД были выявлены и другие ограничения, выявить которые было возможно только
лишь в процессе непосредственного извлечения данных. Например, поисковая
система выдает результаты по 10 на странице. В случае, если их количество
превышает некий лимит, например, 1000, показывается их реальное количество, но
попытка получить результаты для страницы с номером более 100 вызывает ошибку.
Реальный пользователь вряд ли дойдет до 100-й страницы и, увидев слишком
большое количество результатов, просто уточнит свой запрос, а для
автоматизированной системы важно знать подобные особенности поведения и
выработать методы их обхода, например, дополнительное ограничение поиска.
Поскольку чаще всего конечному пользователю предоставляется
механизм именно поиска и отсутствует возможность просмотреть все документы БД,
то запрос приходится разбивать по году публикации, языку и прочим параметрам,
если этих двух оказывается недостаточно. Успешно загруженные данные
целесообразно кэшировать с целью уменьшения количества запросов в случае ошибок
в процессе работы, ведущих к повторному запуску программы сборщика.
После того, как
загружены все сырые данные для источника, производился их анализ. Выявляли
состав полей, анализ их содержимого, определяли, какие из них требуются для
дальнейшей работы, а какие возможно опустить. Счет полей может доходить до
сотен, причем значение большинства из них может никак не использоваться и не
показываться пользователю на странице поиска.
Особо важным моментом является определение полей, содержащих
уникальный идентификатор документа, который однозначно идентифицирует
конкретный документ, а также проверить, реально ли он уникален. Поле с этим
идентификатором значительно облегчает нахождение новых документов по мере их
появления после последующих получений содержимого БД. В случае, если таковое
поле отсутствует, то принималось решение об идентификации документа по
совокупности других полей.
Предлагается выделять для дальнейшей работы следующие поля
из сырых данных источника:
- Вид документа;
- Заглавие;
- Авторы;
- Место издания;
- Год издания;
- Количество страниц;
- Язык документа;
- Ссылки на файлы полного текста (в формате html, pdf и других);
- Ссылка на изображение миниатюры (как правило
изображение заглавной страницы); - Реферат;
- Аннотация;
- Термины тезауруса;
- Международный стандартный номер книги (ISBN);
- Международный стандартный номер сериального
издания (ISSN);
Приведенный список не является полным и может
корректироваться в зависимости от конкретного источника данных. Некоторые поля
могут составляться из нескольких других.
После того, как были определены
основные поля документа, была разработана
структура БД, в которой будут сохраняться обработанные результаты поиска. В
состав полей этой БД как обязательное
было добавлено отдельное поле для хранения даты и времени получения конкретной
записи из внешней системы. Установили,
что целесообразно для данных, полученных за один сеанс работы (в результате
одного запуска программного средства), использовать одно и то же значение даты
и времени, а не точную дату получения каждой отдельной конкретной записи, т.к.
в большинстве случаев работа производится с набором данных целиком, а не каждой
записью отдельно.
Чаще всего для передачи информации в интернет используются
форматы XML и JSON. Например, БД AGRIS принимает информацию в
формате XML. Однако
проблема заключается еще и в том, что одни и те же данные могут быть очень
по-разному представлены внутри самого формата и, соответственно, требовать
различного алгоритма обработки. Довольно часто программисты сериализуют в XML или JSON данные непосредственно в том виде,
в котором они представлены в информационной системе, а не в виде, который
удобен или минимально необходим для отображения пользователю. Это вызывает
накладные расходы и в объеме передаваемой информации и в лишней нагрузке на
устройства пользователя.
В качестве примера можно привести два фрагмента в формате JSON, которые описывают одно и то же заглавие (рис.1 и рис.2).

На рис.1 формат очень прост – данные записаны в виде пар
имя-значение. На рис.2. те же данные
представлены в виде элемента коллекции, состав которой неизвестен заранее,
поэтому введена отдельная пара для имени параметра, и отдельная – для значения
которое может быть текстовым (в другом варианте целочисленным). Значение, в
свою очередь, не единственное, а может содержать массив значений. Обработка
второго примера при помощи любого средства работы с JSON любого языка программирования будет
сложнее и потребует больше действий, чем для первого примера.
При первом запуске программы сбора информации в БД сохраняются
все полученные записи, при последующих запусках отсеиваются уже имеющиеся, и в БД
заносятся только вновь появившиеся записи. Поиск для информирования
пользователей производится только по новым поступлениям.
Несмотря на перечисленные преимущества, у создания локальной
копии есть и свои недостатки. В первую очередь, это объем БД и время, затрачиваемое
на его получение. Если содержимое небольшой базы может быть получено за
разумное время путем последовательных поисковых запросов, то для большой БД это
может быть проблематичным. В этом случае технология применяет частичный поиск по БД. Если при создании локальной копии сначала
извлекают все записи целиком и, затем, для информирования подписчиков
осуществляют поиск по их запросам в полученной локальной БД, то при поиске
посредством инструментов для обычных пользователей в локальной БД создается
подмножество для каждого отдельно взятого поискового запроса. Все документы,
которые отсутствовали в подмножестве во время предыдущего запуска
автоматизированной системы и найдены в процессе последнего, отправляются в
список новых поступлений владельцу поискового запроса. В остальном процесс
разработки поисковой программы, анализа данных источника, разработки структуры
локальной БД практически не отличается от варианта с предварительным созданием
полной локальной копии. Отличия двух подходов схематично представлены на рис.
3.
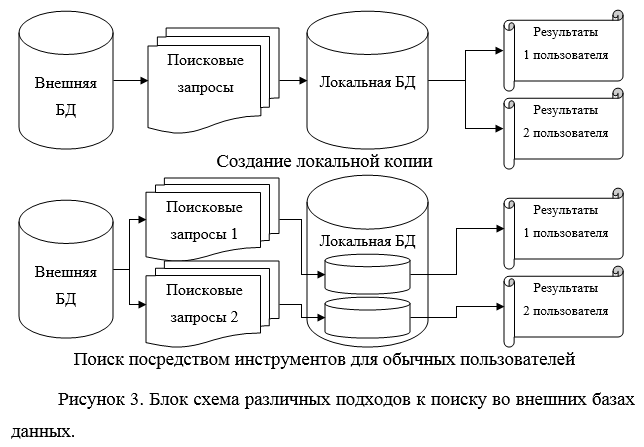
Поиск через API
для разработчиков, при наличии у БД такого API, отличается от поиска посредством инструментов для обычных
пользователей сокращением объема работ по анализу возможностей поисковой
системы, однако, это сокращение очень сильно зависит от наличия подробной
документации. Так, если в документации описывается формат поискового запроса,
возвращаемых результатов, подробно описываются значения возвращаемых полей и их
состав, то не требуется время на самостоятельную обратную разработку такой
информации из полученных данных. Если же, как это часто бывает, вся
документация сводится к паре общих примеров, то объем работ не отличается от полностью
самостоятельного изучения средств поиска конкретной БД.
Очень часто во внешних БД присутствуют собственные средства
оповещения пользователей о новых поступлениях, которые могут называться личным
кабинетом или как-либо еще. Результаты поискового запроса по тематике
пользователя, как правило, присылаются ему на адрес электронной почты. Это
позволяет организовать альтернативный подход к оповещению собственных
пользователей в случае, если другие подходы по каким-либо причинам
нежелательны.
Достоинством данного подхода является отсутствие
необходимости хранить какие-либо данные внешней базы в своей локальной системе,
за исключением административной базы запросов пользователей.
В самом простом случае обработка ведется вручную – сотрудник
библиотеки создает учетную запись на сайте БД и вводит в нее запросы
пользователей. Автоматизированная система получает письма с оповещениями,
разбирает содержащуюся в них информацию и отсылает результаты пользователю.
Однако такой процесс может быть реализован только при небольшом количестве
запросов.
В случае большого числа пользователей и/или поисковых
запросов необходимо произвести обратную разработку личного кабинета БД, а
именно систем авторизации и регистрации подписки на обновления с целью
автоматизации ручного процесса ввода запросов. Необходимо заранее узнать лимиты
личного кабинета, так как наличие небольшого лимита на запросы делает
нецелесообразным реализацию данного варианта оповещения. Либо необходимо
регистрировать для каждого пользователя свой отдельный личный кабинет во
внешней БД.
Разработчику необходимо постоянно следить за работой системы
сбора информации. Для этого создана система регистрации ошибок, протоколы
которой должны регулярно просматриваться. Необходимо протоколировать не только
сетевые ошибки, ошибки протокола HTTP и разбора полученных данных, но и
такие ситуации, которые не являются явными ошибками, но могут свидетельствовать
о некорректной работе системы. Например, ответ сервера на поисковый запрос
может быть абсолютно синтаксически правильным, однако, если в предыдущий раз он
содержал, допустим, 100 записей, а в текущий – ни одной, то это повод проверить
его в ручном режиме, т.к. это может свидетельствовать об изменениях в целевой
поисковой системе и приводить к искажению результатов.
Отдельно рассмотрим случай кардинального изменения в системе
поиска какой-либо конкретной БД. В настоящее время имеет тенденция перехода с
собственных серверов на облачные сервисы наподобие Google App Engine. При этом
полностью меняется API
поиска, URL точек доступа
и формат поисковых запросов и возвращаемых данных. Данная ситуация чаще всего
легко отслеживается в системе регистрации ошибок, т.к. старые URL перестают быть доступны или начинают
возвращать ошибки, но в этом случае требуется повторять целиком весь процесс
обратной разработки от начала и до конца. Также необходимо иметь в виду тот
возможный вариант, что старые точки доступа могут продолжить работать, однако
данные в них обновляться не будут.
Выводы. Описанные
в данной статье проблемы и решения были изучены в процессе выполнения исследований по
разработкепрограммных средств и
технологии сетевой распределенной системы оповещения пользователей о
поступлении документов во внешние базы данных по аграрной тематике.
Информирование пользователей о поступлении информации во
внешние базы данных является сложной задачей. В ходе исследования были выявлены и проанализированы существующие
принципы и технологии функционирования систем оповещения. Изучены механизмы
функционирования поиска таких внешних источников как FAO Documents, баз данных
ProQuest и Springer Nature. Разработаны
программные средства и технология системы оповещения пользователей ЦНСХБ
информацией из внешней БД FAO Documents.
Решены следующие задачи: определены подходы к реализации, произведена обратная
разработка механизмов поиска, определены ее основные ограничения, выявлен
состав полей и произведен анализ их содержимого. Ведется работа по подключению
других источников. В результате выполненных работ авторизированные пользователи
(читатели) библиотеки получат возможность получать оповещения о новых
поступлениях не только в пределах ее
информационных ресурсов, но и во всех внешних источников, подключенных к
системе избирательного распространения информации.
Побочным эффектом работы явилось добавление в состав
электронных фондов ЦНСХБ новой полнотекстовой БД “Публикации ФАО”, которая в
скором времени будет доступна читателям нашей библиотеки для поиска. В ней
содержатся более 68 тысяч документов начиная с 1943 года на английском,
французском, испанском, арабском, русском и других языках.
Литература
- Ивановский А.А. Об особенностях пакетной обработки при
импорте библиографической информации в системе избирательного распространения
информации Библиотеки по естественным наукам РАН // Сборник материалов Международной
научно-практической конференции «Румянцевские чтения — 2018». Российская гос.
б-ка. 2018. С. 345-349. - Ивановский А.А., Ткачева Е.В. Технология современной
системы избирательного распространения информации в Библиотеке по естественным
наукам РАН // Библиотековедение. 2018. Т. 67, № 5. С. 513—522. DOI: 10.25281/0869-608X-2018-67-5-513-522. - Ткачева Е.В. Привлечение читателей к новым формам
обслуживания посредством традиционных инструментов (на примере отдела БЕН РАН в
ГБС РАН) // Сборник материалов Международной научно-практической конференции
«Румянцевские чтения — 2018». Российская гос. б-ка. 2018. С. 156-160. - Ивановский А.А. Источники библиографической информации
в системе оперативного сигнального информирования БЕН РАН в 2016
году//Румянцевские чтения-2017. 500-летие издания первой славянской Библии
Франциска Скорины: становление и развитие культуры книгопечатания: Материалы
Международной науч.-практич. конференции (18-19 апреля 2017, Москва). Ч.1. М.:
Пашков дом, 2017. С. 217-219. - Бунин М.С. Концепция развития Централизованной
электронной библиотечной системы Центральной научной сельскохозяйственной
библиотеки (ЦЭБС ЦНСХБ) // Науч.-информ. обеспечение инновац. развития АПК /
Рос. науч.-исслед. ин-т информ. и техн.-экон. исслед. по инженер.-техн.
обеспечению агропром. комплекса. – М., 2017. – С. 36-42 - Бунин М.С. Стратегия развития Центральной научной
сельскохозяйственной библиотеки // Научные и технические библиотеки. – М.,
2018. – N 2. – С. 5-15.